《Render Hell》 第一部分 概览
这一部分简单介绍了一些 GPU 的涉及的概念。
#Copy the Data
之所以需要在不同的硬件间拷贝数据,是因为从不同硬件中读取数据的速度差异很大。因此对于当前需要频繁访问的数据,通常会选择将其拷贝到更为高速的内存部分中。
GPU 和 显卡 并不是相等的关系 GPU 全称为 Graphics Processing Unit,它指示显卡中的核心计算芯片。整个显卡中还包括显存(VRam),散热器等配件。
对于所有与绘制相关的资源,如贴图,模型,一开始都是存储在硬盘(HDD)上的 。在整个绘制过程中,它们会先被读取到内存(RAM)中,再被读取到显卡上的显存(VRAM)中。之所以要进行这么一个数据从 HDD 拷贝到 VRAM 中的操作,是因为显卡读取 VRAM 中的内容速度更快。整个过程如下所示:
又因为整个过程中数据是被 拷贝 的,因此当数据进入 VRAM 后,在 RAM 中的数据可以被正常销毁,不会影响到后续的绘制。如下所示:
但是 GPU 访问 VRAM 速度仍然不够快,VRAM 中需要使用到的数据会进一步的被拷贝到 GPU 中的一小块内存上( on-chip caches),这一块内存被称为 L2 Cache 。过程如下所示:
在 GPU 更靠近核心(Core)的地方,还有一片更小的内存,称为 L1 Cache 。因为更靠近核心,所以 L1 Cache 中数据的访问速度相对于 L2 Cache 也更快。 L2 Cache 中的数据在需要被操作时,也会先拷贝到 L1 Cache 中。
在 L1 Cache 中的数据还会被进一步拷贝到 GPU 中被称为 Register 的内存区域,GPU Cores 会从该区域中读取数据,计算并将运算后结果放回到 Register 中:
#Set the Render State
对于除了 Mesh 数据外的数据,如顶点/像素着色器,纹理,材质,光照信息,是否半透明等信息都称为 Render State 。
Mesh 数据会使用被设置的 Render State 进行渲染,图形 API 又是一个类似状态机的实现,即设置了 Render State 后,后续的 Mesh 都会使用该 State 进行渲染,直到有了新 State 被设置。示意图如下所示:
#Draw Call
DrawCall 是一个由 CPU 端发出,由 GPU 端接受的绘制 一个 Mesh 的指令。该指令只包含指向需要绘制的 Mesh 的指针,而如材质这样的信息是通过 Render State 进行传递,并不会在 DrawCall 中。示意图如下所示:
#Pipeline
当 DrawCall 发送后,GPU 会获取当前的 Render State,和设置的顶点信息(Mesh),并通过渲染管线(Pipeline)将其一步步转换到最终屏幕上所见像素。在管线中,对于顶点和像素的工作会被划分到 GPU 的多个核心中平行处理。整个管线工作的简单示意图如下所示: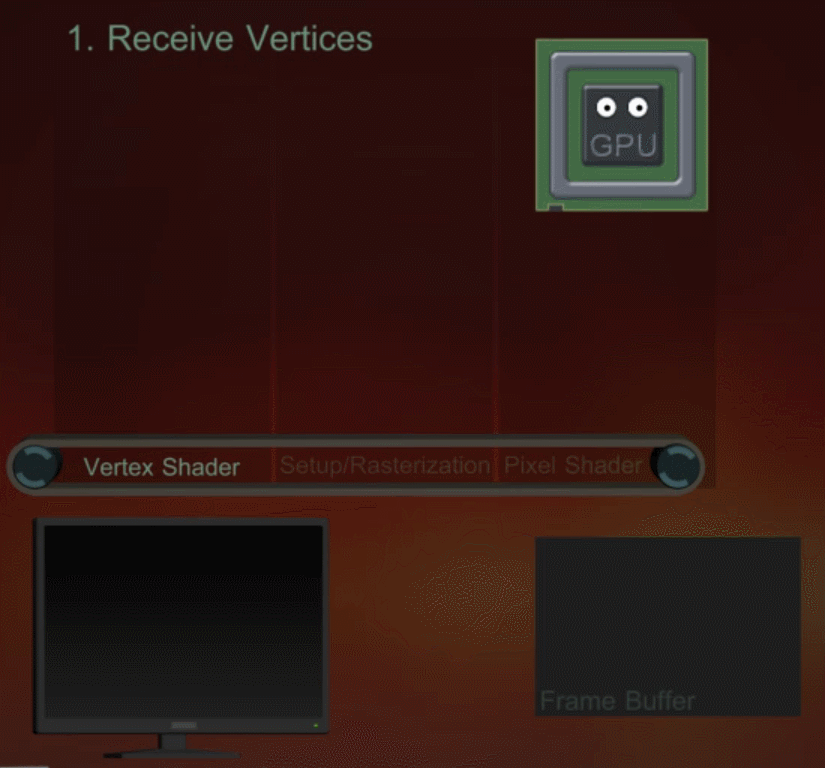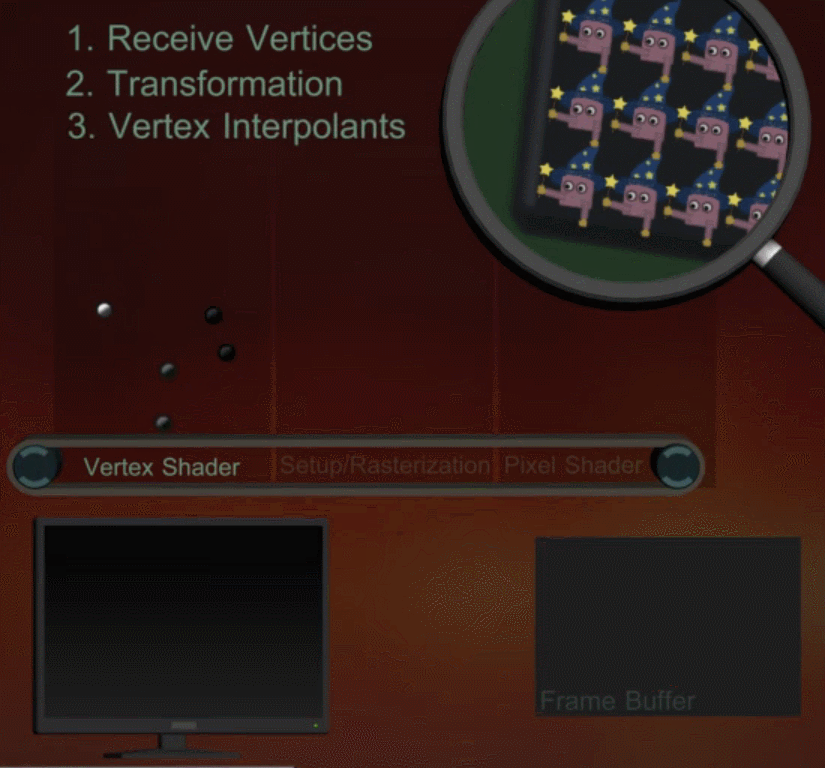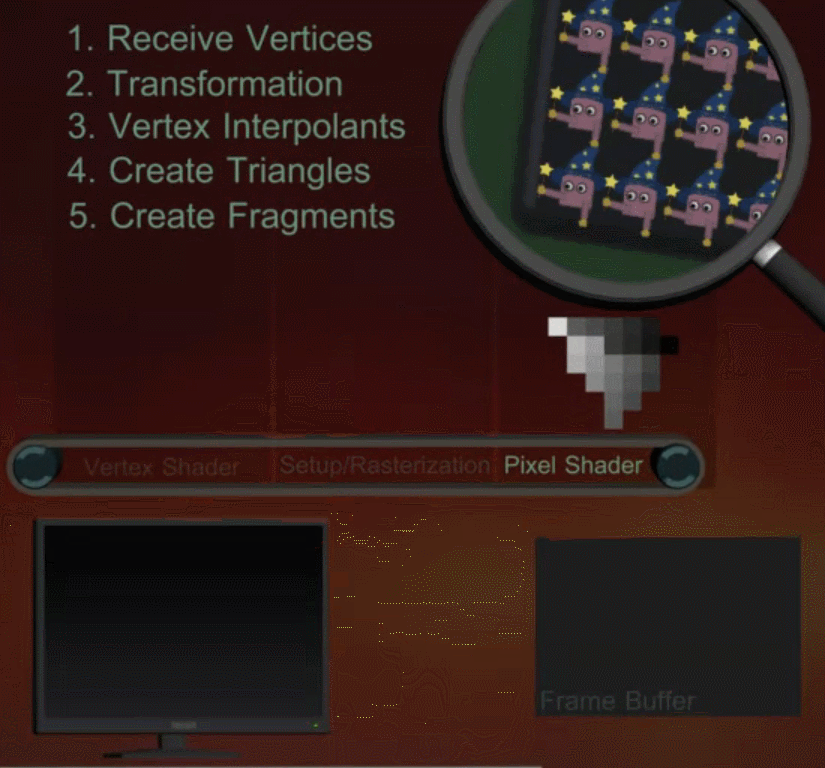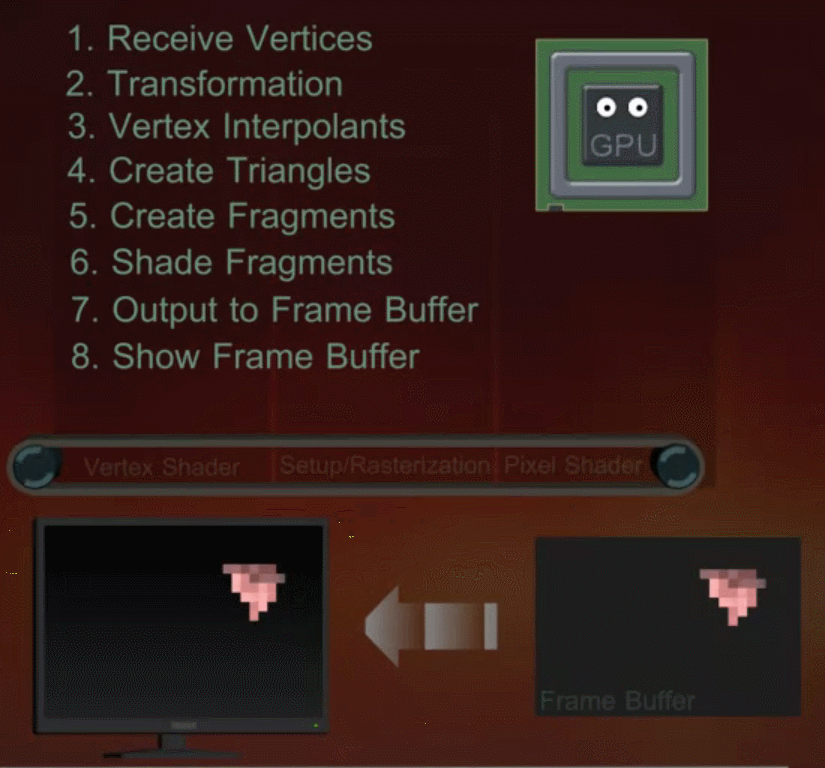
#Command Buffer
CPU 并不是直接将数据传递给 GPU,而是通过 Command Buffer ,这样 CPU 和 GPU 就可以各自独立的工作。如果是直接传递的话,当 GPU 在忙碌时,CPU 无法将数据送给 GPU,就会造成 CPU 的堵塞。
Command Buffer 是一个 FIFO 存储器 ,即 GPU 只会取 CPU 最早 Push 进 Command Buffer 中的数据。 Command Buffer 的示意图如下所示:
#Reference
 wechat
wechat alipay
alipay