《Render Hell》 第二部分 管线
#GPU Core
在 GPU Core 中有两个运算单元 floating point unit(FP UNIT) 和 integer unit (INT UNIT) ,当 GPU Core 接收到数据后,会通过这两个运算单元进行计算。

#Not Everything is done by GPU Cores
对于如分发渲染任务,计算 Tessellation,Culling ,Depth Testing,光栅化,将计算后的 Pixel 信息写入到 Framebuffer 中等工作,并不是不通过 GPU Cores 完成,这些工作会由 GPU 中其他的硬件模块完成(这些模块不受开发者的代码控制)。
#Parallel Running Pipelines
对于 GPU Core 而言,它需要 Streaming Multiprocessor(SM) 为其分配工作,一个 SM 处理来自于 一个 Shader 的顶点或像素数据。因此当一个 SM 下有多个 Core 时,来自于 一个 Shader 的顶点或像素就能被并行的处理。当有多个 SM 时,多个 Shader 间也能并行处理。如下图所示:

#Pipeline Stages In-Depth
这一部分从上至下更深入的讲解 GPU Pipeline
#Application Stage
对于应用而言,其提交的图形 API 都是提交给 GPU 的驱动,告诉其需要绘制的内容和 Render State。
#Driver Stage
驱动会将绘制的数据 Push 到 Command Buffer 中,当 VSync 或 Flush 时,Command Buffer 中的数据会被 Push 到 GPU 中。

#Read Commands
显卡中的 Host Interface 会负责读取 Command Buffer 传递进来的数据供后续的使用。
#Data Fetch
一些 Command 包含数据的拷贝。GPU 通常会有一个单独的模块处理从 RAM 拷贝数据到 VRAM 的过程,反之亦然。这些需要拷贝的数据可以是 Vertex Buffer,纹理或其他 Shader 的参数。通常渲染一帧会从传递 Camera 相关的数据开始。
当所有数据准备完成后,GPU 中会有一个模块(Gigathread Engine)负责处理任务的分发。它为每一个要处理的顶点或像素创建一个线程,并将多个线程打包成一个 Package, NVIDIA 将这个 Package 称为 Thread block 。 Thread Block 会被分发给 SM,如下图所示:
#Vertex Fetch
SM 中仍然包含了多个硬件的单元,其中一个为 Polymorph Engine ,它负责将数据拷贝到各内存部分中,让 Core 在之后的工作中可以更快的访问数据。
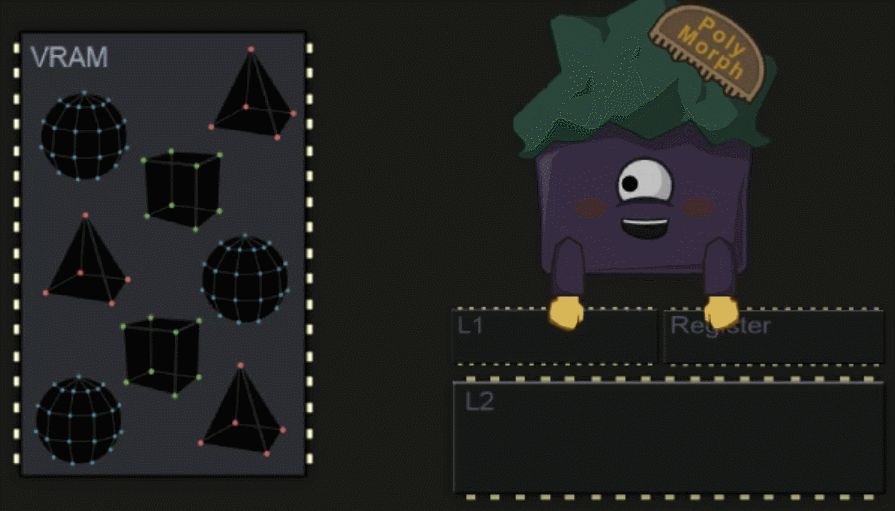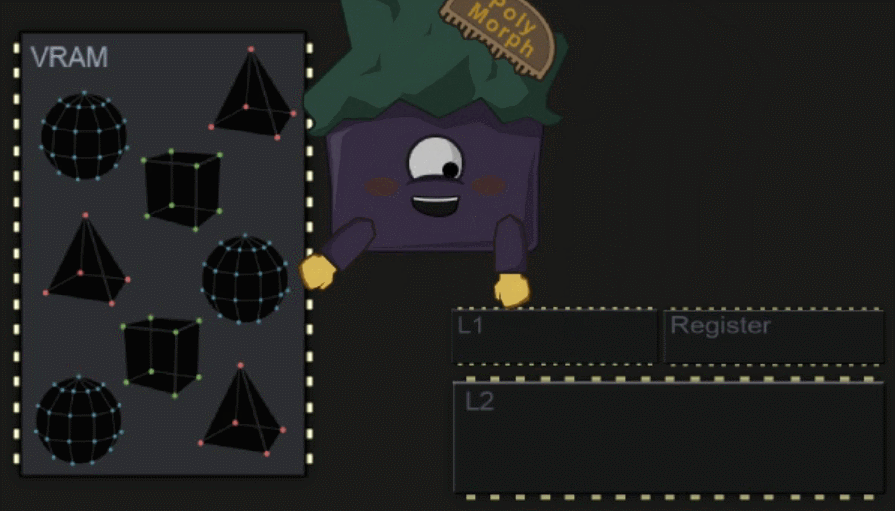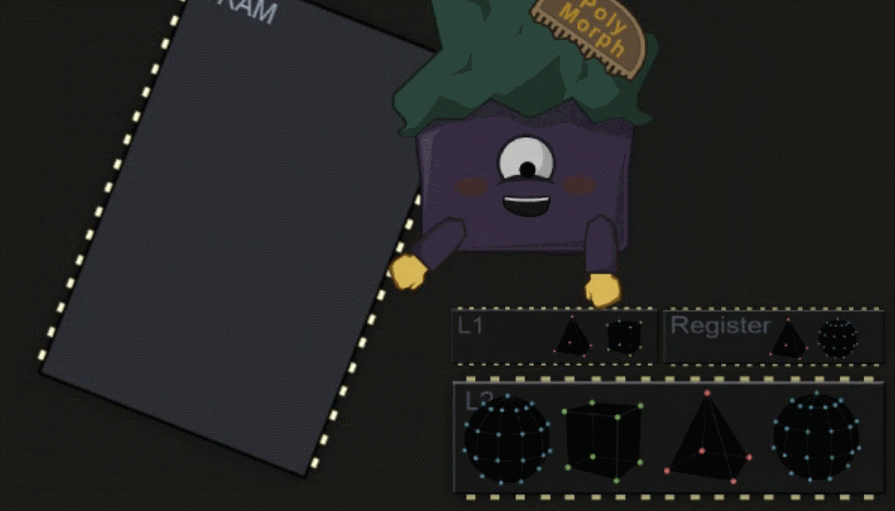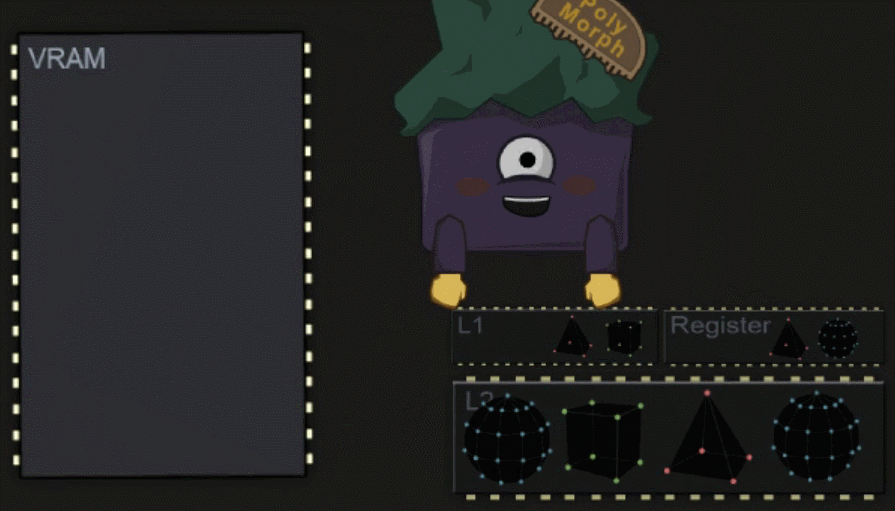
#Shader Execution
Streaming MultiProcessor (SM) 的主要功能为执行开发者编写的 Shaders。
SM 首先会将之前获取到的 Thread Block 拆分为多个 Warp 。每一个 Warp 包含的线程数根据硬件的不同可能存在差异, Nvidia 平台下一个 Warp 包含 32 个 Thread。
SM 中包含多个 Warp Schedulers ,每个 Warp Schedulers 会选择其中一个 Warp,并将需要执行的指令进行翻译。与 Warp 中线程数相同的 GPU Core 会一起逐条执行这些指令。每个 GPU Core 在同一时间点会执行相同的指令,但有着不同的数据(如不同的像素,不同的顶点)。为了简化,如下只展示一个 Warp Schedulers 的情况,过程如下所示:

对于每个 GPU Core 而言,它们无法知晓整个 Shader 指令,它们在仅知晓当前需要执行的那 一条 指令。
需要再次强调的是,一个 Warp 对应的 GPU Cores 在同一时间点会执行相同的指令,不会存在某个时间点一个 Core 执行语句 A,另一个 Core 执行语句 B 的情况。这种限制被称为 lock-step 。
当 Shader 中 IF 指令时,进入分支的 Core 会进行工作,剩下的 Core 会进入“休眠”。同理如果 Shader 中存在循环,那么仍然在循环内的 Core 进行工作,已经完成循环 工作的 Core 进入休眠,直到所有的 Core 都完成了操作。如下所示:
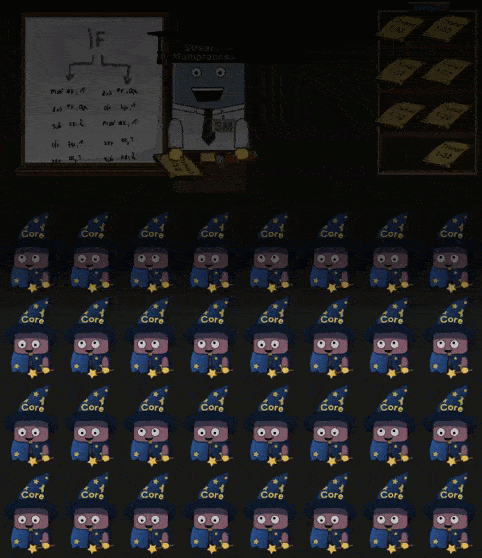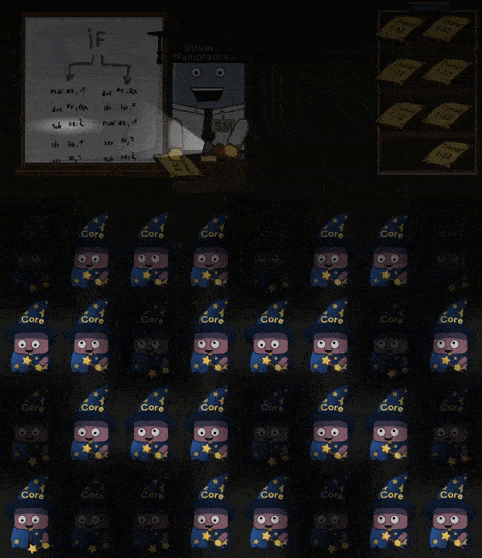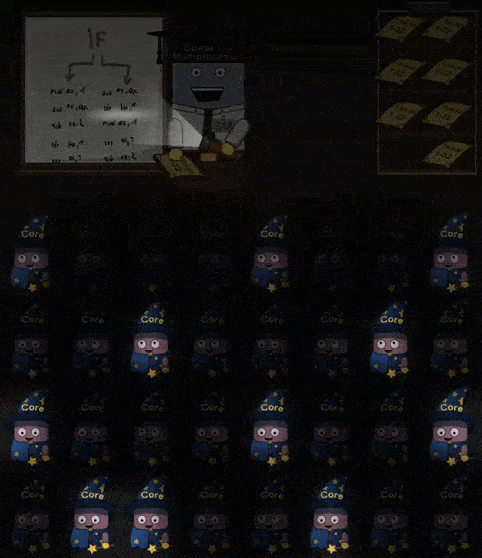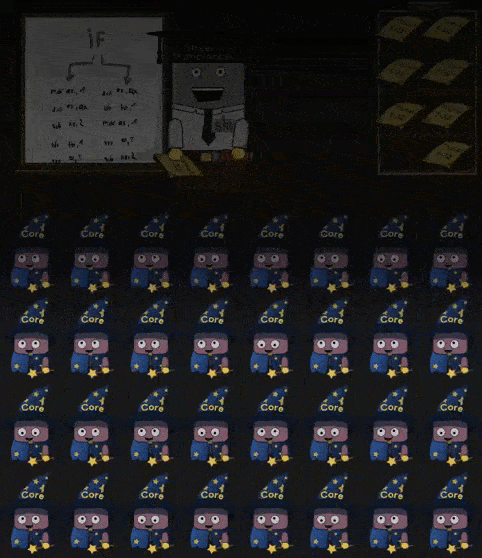
部分 Cores 工作,部分 Cores 休眠的现象称为 divergent threads 应当要尽量避免。
当 Warp 中需要执行的指令依赖的数据尚未被准备好, SM 会选择另一个 Warp 并执行其中的指令,如下所示: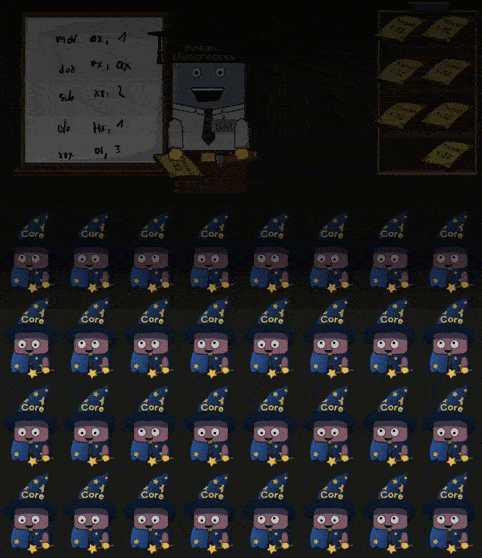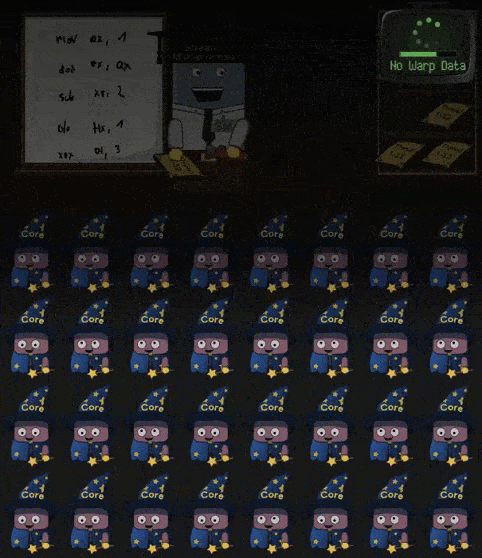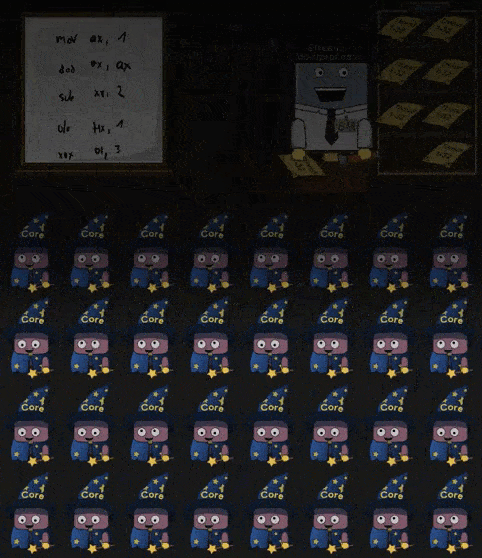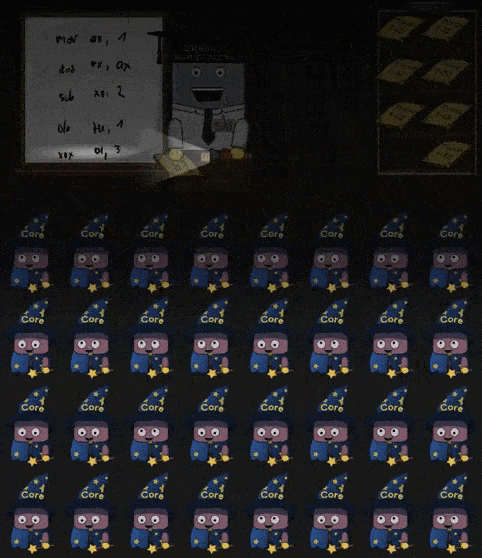
Warp 中指令依赖数据未准备好,必须切换另一个 Warp 继续执行的现象,称为 Memory Stall 。
如前所述,一个 SM 可能包含多个 Warp Schedulers,也因此可以并行的处理多个 Warps,
#Vertex Shader
每一个顶点着色器的实例对应 一个 顶点的处理,且运行在被 SM 管理的一个线程上。
#Tessellation
曲面细分阶段中,有两个可编程的着色器, Hull Shader 和 Domain Shader
为何需要曲面细分阶段,而不是直接在模型中增加更多的顶点?
- 相较于更多顶点时数据传输时的开销,通过曲面细分生成更多顶点的开销更低
- 曲面细分阶段可以控制顶点该如何被细分,如根据摄像机的距离。这样就能产生出更适合实际使用时的顶点数据。
#Patch Assembly
Patch Assembly 和后续的 Hull Shader , Tessellation 及 Domain Shader 仅当使用了 曲面细分着色器(Tessellation Shader) 时才会进行。
Patch Assembly 阶段会把多个顶点打包成一个 Patch 供后续的 Tessellation 阶段处理。究竟多少个 顶点会被打包成一个 Patch,是由开发者决定的,最多 32 个顶点可以被打包成一个 Patch:
#Hull Shader
Hull Shader 处理之前被打包成一个 Patch 的顶点们,并生成一系列的 Tessellation Factor 。这些 Factors 指明了 Patch 中的边该如何细分,和 Patch 的内部该如何细分。
Hull Shader 中也可以指明计算 Factor 的方法,最常见的是根据与摄像机的距离:
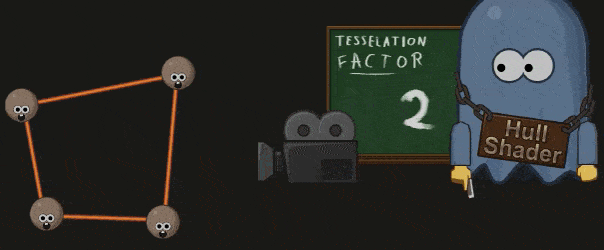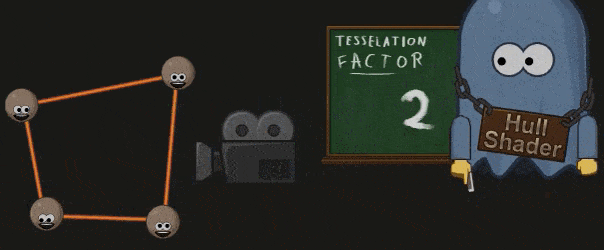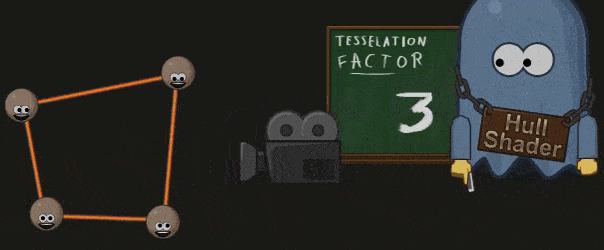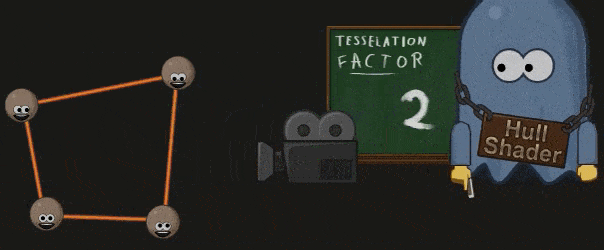
另外因为 GPU 仅能对三个基本的几何元素( Quad,Triangle,Lines)进行细分,Hull Shader 也会指明 Patch 需要按哪个几何元素进行细分。
#Tessellation
Polymorph Engine 会根据之前的 Patch 以及得到的 Tessellation Factor 真正的执行细分操作:
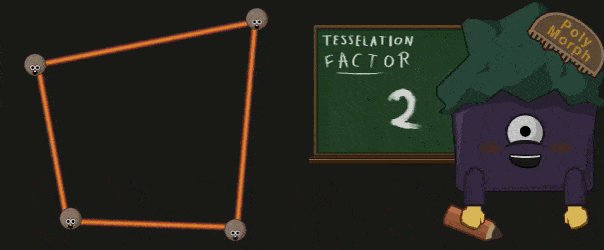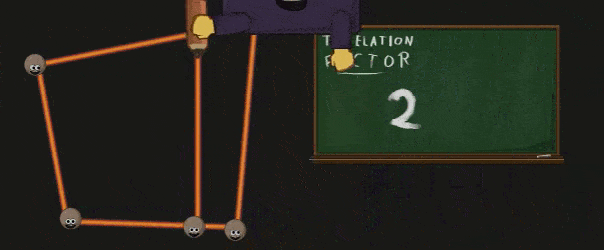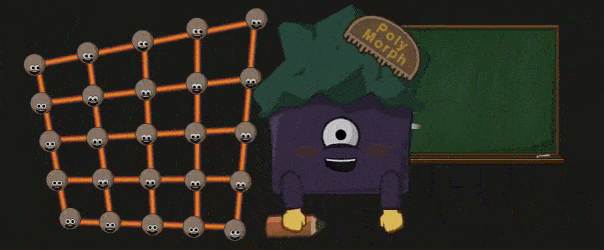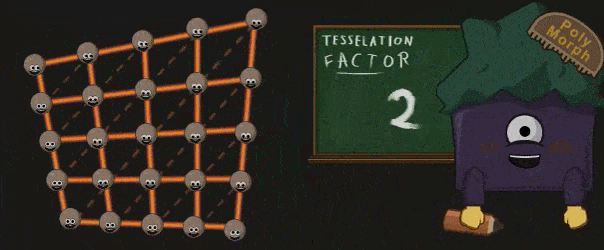
被细分创造出的顶点会被送回到 GigaThead Engine 中,并被其重新派分给 SM,这些 SM 会将得到的顶点通过 Domain Shader 处理。
#Domain Shader
Domain Shader 会根据 Hell Shader 的输出( Patch 顶点)以及 Tessellation 的输出(顶点的质心坐标系( Barycentric Coordinate))调整每个顶点的位置。如果开发者使用了 Displacement map ,则会在这个阶段被使用:
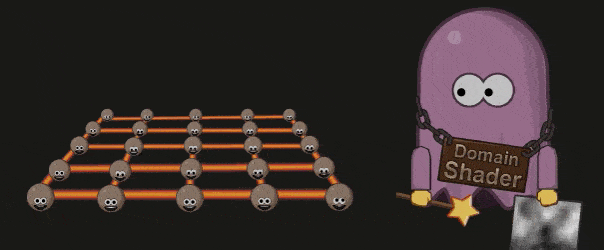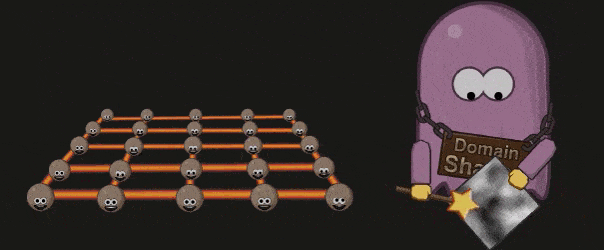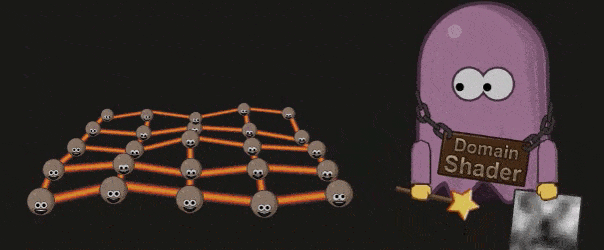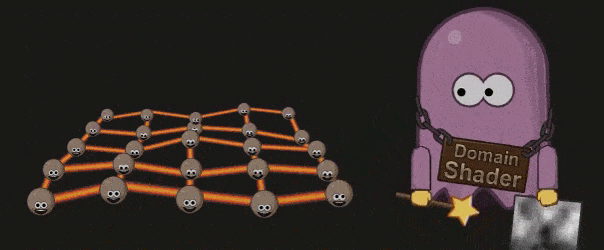
#Primitive Assembly
图元装配阶段,会将顶点数据(来自于 Vertex Shader 或来自于 Tessellation )装配成一个个几何图形:
#Geometry Shader
几何着色器(Geometry Shader)是一个可选 Shadder
几何着色器会针对 Primitive Assembly 给出的图元进行调整,如它可以将一个点调整为两个三角形:

如果需要大量的生成新顶点,更适合在 Tessellation 阶段进行。
几何着色器更大意义在于,它是进入光栅化前最后可配置的一个阶段。如它在 Voxelization Techniques 中扮演了重要角色。
#Viewport Transform && Clipping
之前的操作,物体都是处在 NDC 空间中的。在 Viewport Transform 中需要将其转换到与屏幕分辨率匹配的空间(Viewport 空间),这个操作被称为 Viewport Transform 或 Screen Mapping 。
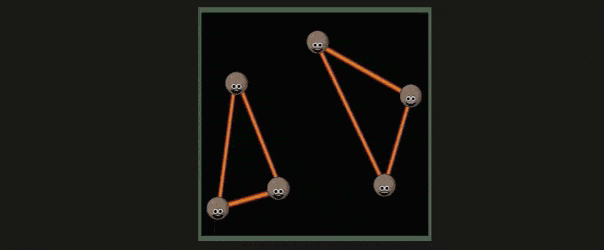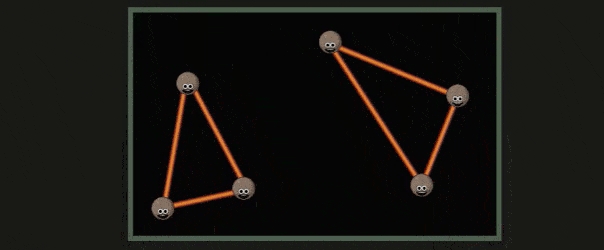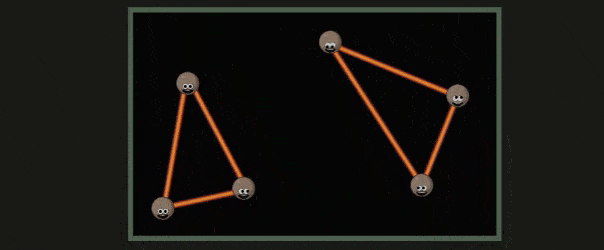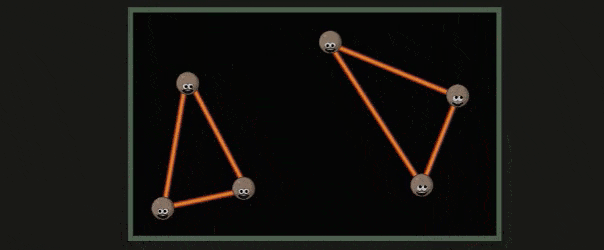
超过了屏幕范围的三角形会被裁剪,这一部分称为 Guard Band Clipping ,如下所示: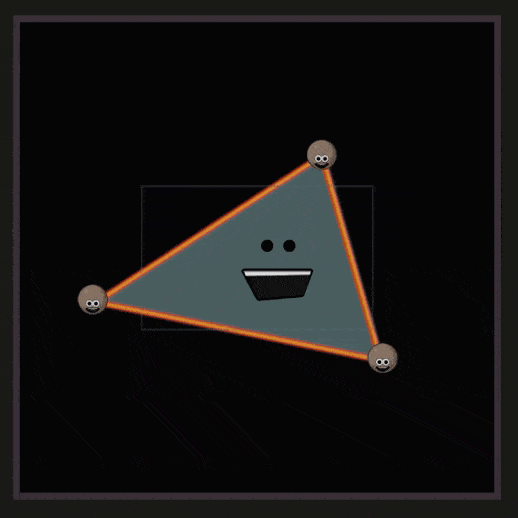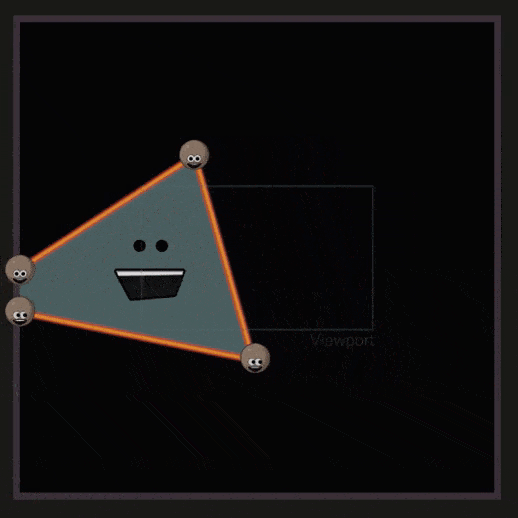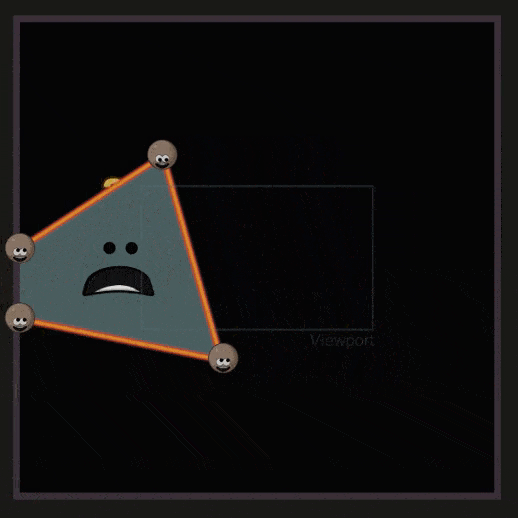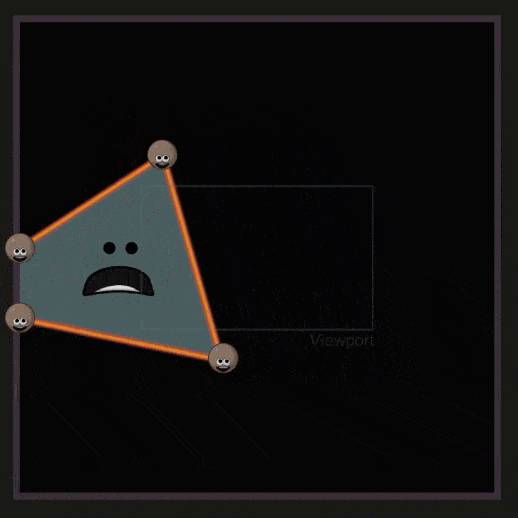
#Rasterizing
在运行像素着色器前,需要通过光栅化,将之前的三角形转换为屏幕上的像素。 GPU 硬件中通常包含多个光栅器,并且他们可以同时工作。
每一个光栅器会负责屏幕中的特定区域,因此 GPU 会根据三角形在屏幕中的位置决定他们应当由哪个光栅器进行处理,并将其发送给特定的光栅器。示意图如下所示:

如果一个三角形足够的大,覆盖了屏幕中的很大一部分,那么可能会同时有多个光栅器为其进行光栅化。
当光栅器接收到一个三角形数据后,它会首先快速的检查该三角形的朝向(Face Culling) 。如果三角形通过了 Face Culling,则光栅器会根据三角形的边,确定它覆盖了那些 Pixels Quad ( Piexls,或称为 pre-pixels / pre-fragment),示意图如下所示:
之所以以 pre-piexles/fragments 作为一个单位,而非单一的 Pixel 作为单位,是因为这样可以计算一些后续操作需要用到的数据(如采样 Mipmap 时需要的导数[1]。
一些 Tile-Based 硬件 ,在 pre-pixels/fragments 创建后,可能会有一些硬件层面上的可见性检测。它们会将整个 Tile 发送给一个称为 Z-Cull 的模块,该模块会将 Tile 中的每个像素的深度与 FrameBuffer 中的像素深度进行比较,如果一整个 Tile 的测试都未通过,则该 Tile 会被丢弃。
#Pixel Shader
对于每个 pre-pixels/fragments ,它们会被 Pixel Shaders 进行填色处理。同样的, Pixel Shader 也是运行在 Warp 的一个线程上。
一个 pre-pixels/fragments 实际上是 4 个像素(),因此一个 32 线程的 Warp,实际上运行 8 个 pre-pixels/fragments 。
当核心工作完成后,它们会将得到的数据写入 L2 Cache。
#Raster Output
在管线的最后,会有称为 Raster Output(ROP) 的硬件模块将 L2 Cache 中存储的 Pixel Shader 运算得到的像素数据写入 VRAM 中的 Frame buffer。
除了单纯的拷贝像素数据, ROPs 还会进行如 Pixel Blending, 抗锯齿时依赖的 Coverage Information 计算等工作。
#Reference
Render Hell – Book II | Simon schreibt.
 wechat
wechat alipay
alipay