《Code Complete》 第五章:构建中的设计
在小型项目中,许多 理论上处于编码外 的活动也会被认为是编码。在一些较大的项目中,架构仅解决了系统级的问题,而将许多设计工作留在编码部分。在真正的大型项目中,前期的设计可能会足够的详细,让编码真正的只需要关心编码本身,但这种详细的设计实际上很少会出现。
设计可以有许多不同的形式,可以是:
- 用伪代码编写类接口
- 绘制类关系图
- 询问另一个程序员哪种设计模式更合适
但无论如何,将设计视作为一项明确的活动都可以让你从中受益。
#5.1 设计挑战
短语“软件设计(Software Design)”是指将计算机软件规范转变为可操作软件的方案的构思、发明或设计。设计是将需求与编码和调试联系起来的活动。
良好的顶层设计提供了一个可以安全地包含多个较低层设计的结构。
设计中包含有许多的挑战,本小节将概述这些挑战。
#设计是一个棘手问题
棘手问题(Wicked Problem) 的定义:如果一个问题,只能通过解决它或者解决它的一部分才能定义,那这个问题就是一个棘手问题。
棘手问题一定程度上存在一些悖论:你在无法定义问题的时候,又怎么能给出一个合理的答案?
所以对于棘手问题,你必须先解决它一次,然后获得它的定义,再真正给出有效的解决方案。
所以软件开发,不能空想。在思考到一定程度后,你就需要动手去做。
棘手问题的一个现实例子:塔科马海峡吊桥
在桥梁设计的时候,主要考虑的因素是桥梁的强度要足以支撑其负载,这个设计要素在建造时也满足了。但建造后不久,桥梁因为大风引起桥身摆动,最终导致共振而坍塌。
在桥梁坍塌之前,工程师并不知道需要考虑空气动力学所引发的共振问题。而只有通过真正建造了这个桥梁(第一次解决问题),工程师们才了解问题中其他需要额外考虑的因素,从而建造起另一种至今仍然矗立的桥梁(第二次真正有效的解决问题)。
#设计是一个马虎过程(即使它产生了整洁的结果)
最终的软件设计应该看起来组织良好且干净,但用于得到这个设计的过程却往往不如最终结果那么整洁。
设计的过程草率的一个原因是,在设计的过程中,你会犯许多的错误,并走进很多死胡同。而这种犯错的过程是合理的,因为在设计过程中犯错并纠正,要比在编码过程中发现错误并纠正,成本便宜的多。正因为一个良好的解决方案和一个糟糕的解决方案之间的差异很小,所以设计过程是草率的,它需要不断的试错。
设计的过程草率的另一个原因是,在设计过程中,你很难知道设计是否“足够好”:你的设计需要包含多少细节,你的设计应该多大程度描述开发中的约束?由于设计是开放式的,所以“设计什么时候足够好” 这个问题的答案,往往是“当你没时间的时候”。
#设计是关于权衡和优先级的
在理想的世界中,每个系统都可以立即运行,不需要消耗存储空间,不占用网络带宽,不会包含任何错误,没有任何的构建成本。但在现实世界中,设计师工作的一个关键部分是权衡上述这些相互竞争资源并在其中之间取得平衡。
如果快速响应速度比最小化开发时间更重要,那么设计人员将选择一种设计。如果最大限度地缩短开发时间更为重要,那么优秀的设计师会精心设计另一个不同的设计。
#设计与限制有关
设计的一部分目的是创造可能性,而另一部分则是限制可能性。
因为我们没有无限的资源和时间,所以我们必须简化解决方案,最终给出改进后的解决方案。
#设计是不确定的
如果你派三个人去设计同一个程序,他们很容易带着三种截然不同的设计回来,而每一种设计都是完全可以接受的。
#设计是一个启发性的过程
因为设计是一个启发性的过程,所以并不是每一步都能产生可预期的结果,它往往依靠“经验法则” 和 “有时有效的尝试”。
设计涉及反复试验。在一项工作中效果良好的设计工具或技术可能在下一个项目中效果不佳。
没有任何工具适合所有情况。
#设计是自然生长的
设计并不是直接从某人的大脑中形成的。他们是通过设计评审、非正式的讨论、编码的经验以及修改代码的经验来逐步发展和改进的。
所有系统在最初的开发过程中都会经历一定程度的设计更改,然后随着扩展到更高版本,它们通常会发生更大程度的更改。
#5.2 关键设计概念
好的设计取决于一些关键概念的理解,本小杰将讨论这些关键的设计概念。
#软件的主要技术要求:管理复杂性
#本质和意外的复杂性
本节中的内容,都是书引用 Brooks(人月神话作者)的观点
Brooks 认为,软件开发之所以变得困难,是因为两类不同的问题——本质问题(Essential Problem)和意外问题(Accidental Problem)。
本质和偶然这两个术语,来自于亚里士多德的哲学:
- 本质属性是一个事物成为该事物所必须具备的属性。汽车必须有发动机、车轮和车门才能成为汽车。
- 意外属性是一个事物恰好具有的属性,这些属性并不真正影响该事物是否是它本身。汽车可以配备 V8、涡轮增压 4 缸发动机或其他类型的发动机,无论细节如何,它都是汽车。
Brooks 认为,软件中的主要意外问题已经被解决了:
- 与编程语言相关的困难,在从汇编语言到高级语言转换的过程中被解决了
- 分时操作系统的出现,解决与非交互式计算机相关的意外困难
同时 Brooks 认为,计算机领域剩下的本质问题的解决会越来越困难。因为计算机必须与复杂、无序的现实世界进行交互。
- 即使我们使用自然语言来进行编程,编程仍然会很困难,因为准确的描述现实世界是如何运作的也存在挑战。
- 随着软件规模越来越大,要解决的现实问题也越来越大,与现实世界的交互也就越来越复杂,而这又增加了要解决的本质问题
所有的问题都来自于复杂性,复杂性也有本质复杂性和偶然复杂性。
Unix 编程艺术 中也有类似的讨论:13.1.3 本质的、选择的和偶然地复杂度
#管理复杂性的重要性
当软件项目调查报告项目失败的原因时,他们很少将技术原因确定为项目失败的主要原因。项目失败最常见的原因是需求不明确、规划不善或管理不善。
但是,当项目因主要技术原因而失败时,原因通常是不受控制的复杂性。
- 该软件变得如此复杂,以至于没有人真正知道它的用途。
- 当一个项目达到没有人完全理解某一领域的代码更改将对其他领域产生的影响时,进度就会陷入停滞。
管理复杂性是软件开发中最重要的技术主题。甚至,软件的首要技术要求必须是管理复杂性。
Dijkstra(1972 年图灵机获得者)说没有人的大脑大到足以容纳一个完整的现代计算机程序。因此作为开发者,不应当将记住一个软件所有的细节作为目标。计算机程序的构建模式,应当可以让开发者可以在一段时间内安全的只关注于其中的一小部分。作为开发者的目标,应当是减少自己在任何时刻必须考虑的程序量。
One symptom that you have bogged down in complexity overload is when you find yourself doggedly applying a method that is clearly irrelevant, at least to any outside observer. It is like the mechanically inept person whose car breaks down—so he puts water in the battery and empties the ashtrays.
—— P. J. Plauger
在软件架构层面,可以通过将系统划分为子系统来降低问题的复杂性。人类更容易理解几条简单的信息,而不是一条复杂的信息。所有软件设计的目标都是将复杂的问题分解为几个简单的部分。子系统越独立,开发者就越能安全地一次专注于一处的复杂性上。
#如何应对复杂性
出现 开发成本过高,效率低下 的设计,通常是如下三个原因:
- 对简单问题用了复杂的解决方案
- 对复杂问题用了简单但错误的解决方案
- 对复杂问题用了不恰当的复杂的解决方案
现代软件本质上是复杂的,无论你多么努力,你最终都会遇到现实世界问题本身固有的某种程度的复杂性。这建议采用双管齐下的方法来管理复杂性:
- 最大程度减少任何开发者在处理任务问题时必须处理的复杂性
- 防止不必要的意外复杂性增长
一旦了解了软件设计中,其他的技术目标相对于管理复杂性都是次要的,许多设计考虑因素都会变得简单。
#设计的理想特征
高质量的设计具有几个一般特征。如果你的设计能实现所有这些目标,那这个设计就是一个非常好的设计。有些目标与其他目标相矛盾,但这就是设计的挑战——从相互竞争的目标中创建一套良好的平衡。
When I am working on a problem I never think about beauty. I think only how to solve the problem. But when I have finished, if the solution is not beautiful, I know it is wrong.
—— R. Buckminster Fuller
以下是一些高质量设计的特征:
- 最小复杂度:设计的主要目标应该是最小化复杂性。避免做出“聪明”的设计,“聪明”的设计通常很难理解。相反,要做出“简单”和“易于理解”的设计。
- 易于维护:易于维护意味着解决方案是为未来维护这段代码的程序员而设计。不断想象维护的程序员会询问的关于你正在编写的代码的问题。将维护程序员视为你的受众,然后你编写的系统就会不言自明。
- 松耦合:松耦合意味着设计时应将程序不同部分之间的连接保持在最低限度。最小连接性可以最大限度地减少集成、测试和维护期间的工作。
- 可扩展性。可扩展性意味着你可以增强系统而不会对基本结构造成破坏。你可以更改系统的一部分而不影响其他部分。对于最有可能发生的变化,在设计中已经考虑,因此这些变化对系统造成的伤害最小。
- 可重复使用性:可重用性意味着你的系统可以在其他系统中重用它的各个部分。
- 高扇入(High fan-in):高扇入意味着系统被设计为充分利用系统较低级别的 Utilities 类。
- 中低扇出(Low-to-medium fan-out):中低扇出意味着每一个类都使用中低数量的其他类。如果一个类使用 7 个以上的其他类,则说明该类存在高扇出,即该类过于复杂。
- 可移植性:可移植性意味着系统可以轻松地将其移动到另一个环境中。
- 精益(Leanness):精益意味着设计的系统没有额外的部件。伏尔泰说,一本书完成时,不是不能再添加任何东西,而是不能再删除任何东西。
- 分层(Stratification):分层意味着保持各层次的解耦。在设计好的系统中,你应当可以在某一个级别查看细节,而不需要深入到其他的级别中。
- 例如,如果您正在编写一个必须使用大量旧的、设计不良的代码的现代系统,请在新系统中编写一个负责与旧代码进行交互的层。设计该层,使其隐藏旧代码的低质量,为新层提供一组一致的 API。然后让系统的其余部分使用这些新类而不是旧代码。
- 标准技术:一个系统越依赖特异的实现。对于第一次尝试理解它的人来说就越令人生畏。尝试通过使用标准化、通用的方法来让整个系统给人带来熟悉的感觉。
#设计的层次
软件系统需要在几个不同的细节层次上进行设计。有些设计技术适用于所有级别,有些仅适用于一两个级别。
系统的第一层次为系统本身,第二层次为组成系统的子系统或 Packages,第三层次是组成 Packages 的类,第四层次是组成类的方法和数据,第五层次是类内部的方法设计。如下图所示: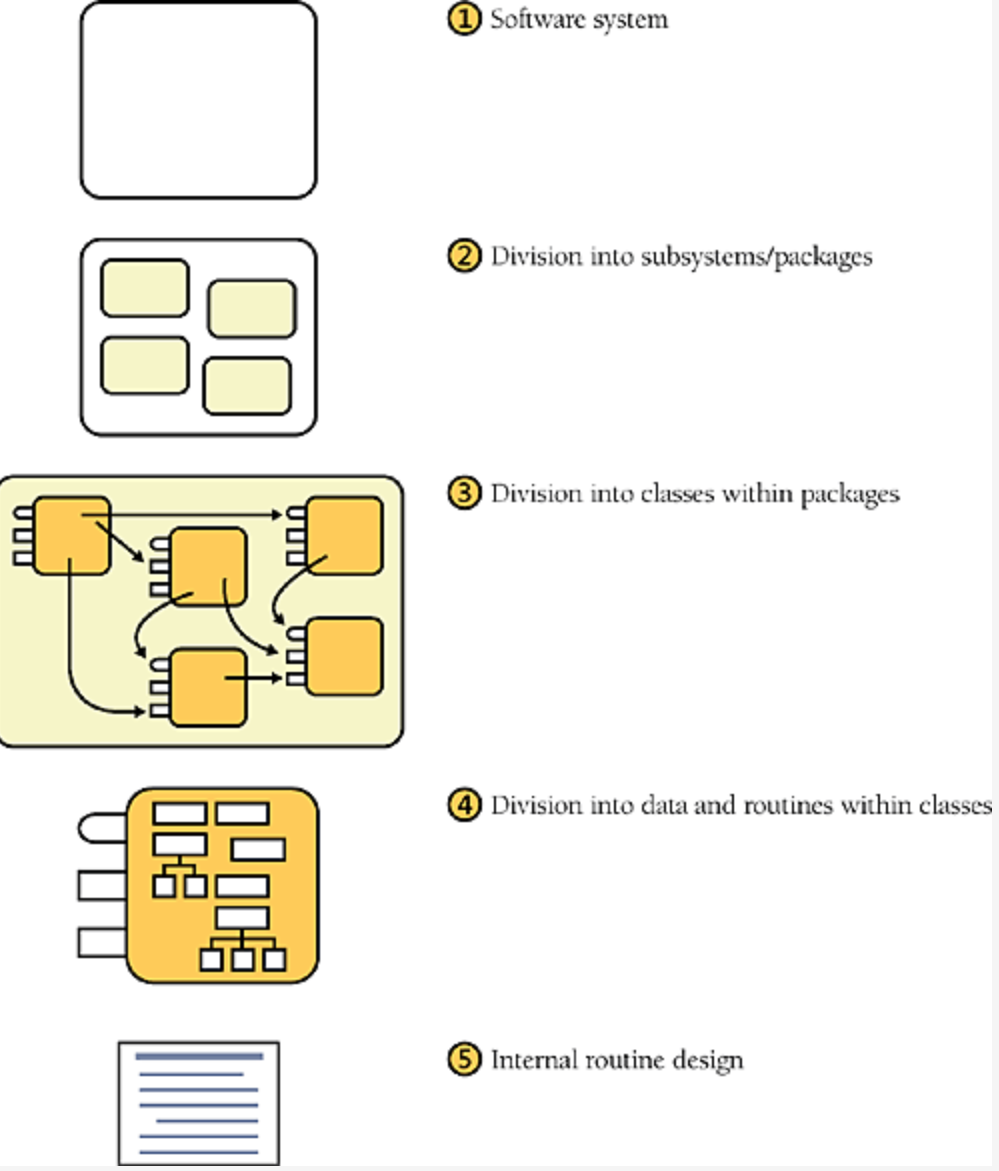
#第一层次: 软件系统
设计的第一层次是整个系统,在这一层次中通常不会有太多的设计。
#第二层次:子系统或包
第二层次的设计目标主要是识别主要的子系统。该级别的设计活动是决定如何将程序划分为几个主要的子系统,以及定义每个子系统在何种程度上允许使用其他的子系统。
- 对于需要持续几周的项目,通常都需要进行这个级别的划分。
在此级别中,定义各个子系统如何通信的规则特别重要。如果所有子系统都可以与所有其他子系统通信,那么就失去将它们分开的好处。通过限制通信使每个子系统变得有意义。
只有当两个子系统“需要知道”彼此时才放开通信,而且这个 “需要知道” 最好也有个充足的理由。如果没法确定是否应该放开通信,在一起开始指定严格的通信标准,并在实践中逐步放开,也比一开始任意通信,然后在有数百个子系统间通信时再尝试收紧要好。
为了使连接易于理解和维护,最好选择简单的子系统间的关系。
- 最简单的关系是一个子系统调用另一个子系统的接口。
- 一种更复杂的关系是让一个子系统包含另一个子系统的类。
- 最复杂的关系是一个子系统中的类继承另一个子系统中的类。
- 不应该出现循环依赖,即 A 依赖 B,B 依赖 C,C 依赖 A 的情况出现。
#第三层次:类
这个层次的主要设计活动,是确保已有的子系统都已经分解到了足够详细的程度(详细定义了每一个类暴露的接口),以便开发者可以用单独的类来实现其中的一部分。
如果一个项目很大,那么第三层次的划分与第二层次的划分将有明显的差异。而如果项目很小,则可能跳过第二层次的划分,直接进入第三层次。
#第四层次:函数(Routine)
在第三层次中,应当完成定义每一个类暴露的接口。而在这一层次,则应该定义类中所有的函数。
定义类中所有函数的过程,通常可以让开发者更好的理解类的接口,并对接口进行相应的调整(回到第三层次)。
#第五层次:函数的内部设计
在这一层次中,开发者需要设计每一个函数的实现,在设计过程中会进行编写伪代码,查找算法等一系列活动。
第五层次的设计总是会完成的(毕竟你需要写出代码),尽管设计有时是无意识地、糟糕地完成,而不是有意识地、良好地完成。
#5.3 用启发式的方式进行设计
程序员往往倾向于算法“做 A,B,C, 然后你会得到 X,Y,Z“,当一样的步骤产生了不一样的结果后,程序员会感到恼火。这种对确定性的渴望,非常适合于编程的过程。
但在软件设计时,则完全不同。由于设计是不确定的,因此熟练应用一组有效的启发式方法是优秀软件设计的核心活动。
算法是一组用于执行特定任务的明确定义的指令。算法是可预测的、确定性的,并且不受偶然性的影响。算法会告诉你如何从 A 点到 B 点:不走弯路,不绕道到 D、E 和 F 点。
———— 《Code Complete》第二章:丰富软件开发理解的隐喻
启发式是一种帮助您寻找答案的技术。其结果可能会受到偶然性的影响,因为启发式方法只告诉您如何查看,而不是告诉您要查找什么。它不会告诉你如何从 A 点直接到达 B 点;它甚至可能不知道 A 点和 B 点在哪里。
———— 《Code Complete》第二章:丰富软件开发理解的隐喻
以下是一些启发式的进行设计的方法:
以下是一些进行软件设计时,可以考虑的方向,期望这些方向可以启发你对于软件设计的思考。
这些方向不是相互冲突的,相反,你可以将他们结合起来思考
#寻找现实世界的物体进行参考
设计的第一种也是最流行的方案就是“按字面意义的”进行面向对象设计,即识别现实世界并设计对象。
识别的步骤为:
- 识别对象及其属性
- 确定可以对每个对象执行哪些操作
- 确定每个对象可以对其他对象执行哪些操作
- 确定每个对象的哪些部分对其他对象是可见的——哪些部分是公共的,哪些部分是私有的
- 定义每个对象的公共接口。
#形成一致的抽象
抽象是指在理解概念的同时安全地忽略其某些细节的能力——在不同级别处理不同的细节。从复杂性的角度来看,抽象的主要好处是它允许您忽略不相关的细节。大多数现实世界的对象已经是某种抽象,比如房子是窗户、门、壁板、电线、管道、绝缘材料以及组织它们的特定方式的抽象。
在现实生活中,人不断的在使用抽象。如果出门时你要进行的不是拧把手,而是要处理木纤维,清漆分子和钢分子,那你将很难出门。
但开发者软件有时会在木纤维、清漆分子和钢分子级别构建系统(没有进行合理的抽象),这就使得系统过于复杂并且难以管理。
#封装实现细节
封装是抽象的延续: 抽象 说,“你可以以高维度的方式(忽略细节)观察一个物体。 封装 说:“此外,您不允许以任何其他维度观察对象。你现在看到的一切就是你被允许看到的一切”
#继承
继承简化了编程,因为开发者可以编写通用的方法来处理通用属性的任何内容,然后编写特定方法来处理特定的操作。
#隐藏信息
在结构化设计中,“黑匣子”的概念来自于信息隐藏。
在面向对象设计中,信息隐藏产生了封装和模块化的概念,并与抽象的概念相关联。
信息隐藏的特点是软件开发人员将“秘密”、设计和实现决策隐藏在一个地方,不让程序的其余部分看到。
信息隐藏是对隐藏复杂性的强调。
#秘密和隐私权
设计类的一项关键任务是决定其中的哪些信息应该在类之外为人所知,而哪些信息应该保密。
- 一个类可能使用 25 个函数,并且仅公开其中 5 个,在内部使用其他 20 个。
- 类的接口应该尽可能少的展示其内部工作原理。
#隐藏细节的一个示例
比如程序中需要为每一个对象分配一个唯一 ID。一个最简单的思路是在全局变量中定义一个 g_maxId 表示当前最高的 ID,然后在每个对象的构造函数中,使用 id = ++ g_maxId。但这个实现可能会遇到如下的麻烦:
ID 的创建方式变更
如果对于 ID 的分配有了新需求,比如需要为特殊的对象保留 ID 范围,或者需要使用非连续 ID 来提高安全性,或需要重用已经被销毁的对象的 ID。
此时就需要修改id = ++ g_maxId语句,而它遍布在了整个程序各种对象的构造函数中,因此修改会很麻烦。针对该方法的解决方法可以是,使用一个全局的函数来分配 ID,如
id = GetNewId(),然后在各个对象的构造函数中调用该函数。这样,如果 ID 的分配方式变更,只需要修改GetNewId()函数即可。这样的实现就隐藏了信息,隐藏了 “ID” 是如何分配的信息。
ID 的类型发生了变化
如果 ID 的类型从
int变成了string,那么即使存在GetNewId函数也不能解决问题,因为整个程序中的id变量都是int类型的,因此修改范围仍然是整个程序。针对该问题的解决方法是,定义一个类来表示 ID,而 ID 的具体实现细节则隐藏在该类中。这样,如果 ID 的类型发生了变化,只需要修改 ID 类即可。
这样的实现也隐藏了信息,隐藏了 “ID” 是什么类型的信息。
隐藏信息会让实现变得更加复杂,因此隐藏信息并不是一种万能的解决方案,而是一种权衡。
#两类秘密
有两类实现中的秘密需要被隐藏:
- 复杂性:将复杂的实现隐藏起来,这样开发者的大脑就不需要关系它。除非开发者真的需要关心它(如要修改实现),它可以自己点进去。
- 变化:将可能发生变化的实现隐藏起来,这样当变化发生时,只需要修改隐藏的实现即可,即让变化的影响限定在了局部。
#隐藏信息的障碍
在某些情况下,信息隐藏确实是不可能的,但信息隐藏的大多数障碍都是由于已经使用或习惯使用其他技术而面对要大规模修改时产生的心理障碍。如下是一些障碍:
信息已经过度传播:信息隐藏的一个常见障碍是整个系统中信息已经过度分布,这里的信息可能是:
- 硬编码:整个系统中可能已经充满了诸如 100 这一的 magic number,导致修改的工作量很大。最好使用将 magic number 隐藏在一个常量之中。
- 交互模式:如果整个系统的信息与 UI 交互强绑定,那么当交互模式发生变更时,几乎所有代码都必须重新修改。最好将用户的交互集中在单个的模块中。
- 全局变量:假设程序中有一个大小为 100 的数组表示员工数据,整个程序都访问该数组进行数据的填充。在这种情况下,整个系统都强耦合了“大小为 100 的数组” 这个信息,一旦整个数据结构发生了变化,整个系统都需要变更。
循环依赖:如果存在两个类 A 和 B,A 的函数调用 B 的函数,B 的函数调用 A 的函数。那么进行信息隐藏时,你很难进行测试:你最少得保证 A 和 B 的一部分已经准备就绪,否则你无法测试 A 和 B。
对类成员数据的恐惧:部分严谨的程序员,会将类成员数据看作为全局数据并避免它。但很大程度上,类成员数据的危害要比全局数据小得多。
The road to programming hell is paved with global variables.
全局数据主要有以下两个问题:
- 一个函数在操作全局数据时,并不知道是不是有其他的函数也在操作它
- 一个函数在操作全局数据时,即使它知道其他函数也在操作它,但它仍然不知道其他函数在对这个数据进行什么操作。
但类成员数据大程度上,减少了上述两个问题的发生,因为对一个数据的访问者被限定在这个类中。
上述关于类成员数据危害比全局数据小得多 的结论前提是,整个程序使用 设计良好,小型 的类。如果整个程序都基于几个大型的类,那么类成员数据与全局数据的定义就变得非常模糊了
- 对性能惩罚的恐惧:有些程序员认为,隐藏信息会导致性能下降,如封装了太多的类,会导致内存的频繁分配等等。但设计一个“隐藏信息”的系统,和设计一个“性能良好”的系统并不冲突,在设计系统时完全可以同时考虑这两个目标。
在你能够明确的测量出性能瓶颈前,对于性能的担忧都是过早的。此时你能做到,应该是尽可能的将代码模块化,以保证后续检测到性能瓶颈热区时,对它的修改不会影响到整个系统。
#隐藏信息的价值
信息隐藏是少数在实践中无可争议地证明其价值的理论技术之一,学术界在多年前就发现使用信息隐藏的大型程序比不使用信息隐藏的程序更容易修改。
针对信息隐藏的思考,与传统的面向对象的设计思路可能存在差异。
- 在使用面向对象的思考模式时,你不会想到应该将 ID 封装在
IdType中,而不是直接使用 int。如果声明了IdType,常常意味着需要定义构造函数,析构函数,赋值运算符等等一系列代码,绝大部分的程序员会认为 “不,不值得仅仅为一个 ID 创造整个类,使用整数就好” - 针对信息隐藏的思考,则会提出一个问题 “ID 的数据应该被其他模块感知吗?”,这个问题在面向对象思考模式时,是不会出现在程序员脑子中的。
对于大部分的程序与,在设计类接口时,往往也只是考虑“外部接口怎么调用最方便”,这通常会导致类暴露越来越多的接口。而针对信息隐藏的思考,则会提出一个问题 “这个类需要隐藏什么?”,这个问题可以帮助类设计时将更多的操作隐藏在被暴露的接口中,而不泄露其具体实现。
询问自己“哪些信息需要被隐藏”,可以在各种帮助实现各种级别的良好设计:
- 编码级别会更容易使用常量而不是硬编码的 Magic number
- 函数级别会更容易定义少量的、必须的形参
- 类级别会更容易设计出只暴露少量的、必须的接口
- 系统界别会更容易考虑各模块和子系统间的分解、连接策略。
养成问自己 “我应该隐藏什么?”的习惯。你会惊讶地发现有多少困难的设计问题迎刃而解。
#确认可能发生变化的领域
一项针对伟大软件设计师的研究发现,他们的一个共同属性是预测变化的能力。
针对容易变化的程序,你应该遵循以下的步骤:
- 确认可能会更改的部分:如果完全遵循 3.4 前期准备:需求,那需求中应当包含有对可能发生变更的部分的描述。如果需求没有,则你需要在设计时重新审视。
- 将容易变更的部分与项目的其他部分分开:将容易变更的部分划分为自己的类或组件,以保证它和其他部分相独立
- 将容易变更的部分隔离:将容易变更的部分的接口设计为对潜在的变更不敏感。让这些变更内容局限在接口的实现内部,以保证外部并不会被变更影响。
以下是一些容易发生变化的领域:
- 商业规则:如费率,折扣策略等商业的规则极容易发生变化,应当将这些部分拆分出来(或者使用表驱动)
- 硬件依赖:将对硬件的依赖隔离在类或子模块中,以保证当程序迁移到新硬件时,不需要关注太多的依赖
- 编码困难的地方:如果你在设计或编写某段代码时,发现这一部分很难(无论难在设计,算法还是具体的实现),那就说明你很可能这一段写的不好,你很可能需要重新做。因此将这部分隔离开来,并尽可能减少它的不良设计。
- 状态变量:建议使用 Enum 表示状态,状态很可能会新增,如果使用类似 bool 值来表示状态,则再拓展时会发生问题。
- 使用函数来检测状态,而非直接对状态变量进行访问:使用函数来检测状态意味着可以进行更复杂的检测,如果你的状态检测与其他的数据相耦合,那么这个信息应当封装在函数中。
在考虑可能变更的部分时,也要将后续的程序质量提升(如增加线程安全机制,增加本地化机制)等考虑在内,这些地方存在潜在的优化,也意味着这些地方存在潜在的变化可能。
#保持松耦合
耦合描述了一个类或函数与其他类或函数交互的紧密程度。耦合的概念同样适用于类和函数,因此在本节中,将使用 模块 一词来指代类和函数。
如果模块之间的耦合足够松散,那么一个模块可以很容易的被其他模块所使用:
sin(float angles)是足够松耦合的,调用者知道只需要传入一个表示角度的 float 值即可InitVars(var 1,var 2, ...,var N)这样的函数就是紧耦合的,因为调用者需要知道这些需要传入的形参究竟是什么
#耦合标准
以下是几个评估模块之间耦合程度的标准:
#连接数量
模块之间的连接数量越多,两个模块就越耦合。
有 6 个形参的函数比有 1 个形参的函数与调用者的耦合紧。
有 30 个 public 函数的类比有 4 个 public 函数的类与调用者更耦合。
#可见性
模块之间的连接关系越明显耦合度越低。
比如 A 函数的处理依赖于 B 函数的处理。耦合最低的方式,是将 B 函数的输出作为 A 函数的输入;耦合最强的方式,是 B 函数修改一个全局变量,A 函数再处理这个全局变量。
直观上,A 函数的输入依赖 B 函数的形参,是一个强耦合。
但实际上这样的操作,让 A 并不需要关心 B 的具体实现,A 只要求其他函数提供满足要求的输入即可,提供输入的函数可以是 B,也可以是 C,所以实际上这样的做法是弱耦合。
#灵活性
灵活性是指模块间相互调用的便捷程度,灵活性越高,耦合越低。
灵活性一定程度上是通过封装来实现的,如 U 盘是电线和芯片的封装,它带来了与电脑的连接灵活性。
有的时候,封装则会降低灵活性质。如果有一个函数 LookupVacationBenefit 用以查询员工的假期福利,假期福利取决于员工的入职时间和工种。一种常见的做法是将函数的形参定义为 employee 类型,即传入一个员工类型,返回该员工的假期福利。看起来这个实现耦合度很低,因为它有足够低的 连接数量。
如果此时,有另一个模块(如招聘网站)想要查询假期福利,它有入职时长和工种的数据,但它并没有员工数据。此时它想要调用 LookupVacationBenefit,就只能实例化一个临时的 employee 对象。但这样可行的前提条件是,该模块需要了解 LookupVacationBenefit 的实现细节,即该函数只用了 employee 中的入职时长和工种两个数据,而没有用到其他的数据。这破坏了 可见性 原则,即带来了高耦合。
这个例子即为后续会提到的 语义耦合
#耦合类型
模块间有以下几种耦合类型:
#简单参数数据耦合
如果两个模块间传递的数据都是原生数据类型,且所有数据都通过参数列表传递,则称为 简单参数数据耦合(Simple-data-parameter coupling),这种耦合通过是 正常且可以接受的。
#对象参数耦合
如果对象 1 要求对象 2 向其传递对象 3,则两个模块之间是 *对象参数耦合(Object-parameter coupling)*的。
这种耦合比 简单参数数据耦合 耦合程度更高,因为它要求对象 2 了解对象 3(对象 2 要负责对象 3 的创建)。
#语义耦合
如果一个模块不依赖另一个模块的成员,而是依赖其内部工作的一些结果,则这两个模块间是 语义耦合(Semantic Coupling)。
以下是一些语义耦合的例子:
Module 1将一个 Magic Number 传递给Module 2,以此告知Module 2应该要执行的操作。这个行为假设了Module 2能理解Module 1的 Magic Number。
如果传递的不是 Magic Number,而是枚举值,则不算是语义耦合
Module 2在Module 1修改了全局变量后,使用该全局变量的值。这个行为假设了Module 1会修改全局变量,且Module 2能理解Module 1对全局变量的修改。Module 1的接口声明中表示了调用routine函数前,必然会先调用initialize。所以Module 2直接调用了routine而未调用initialize。这个行为假设了Module 2能理解Module 1的接口声明,且Module 1的行为不会发生改变。Module 1将 Object 传递给Module 2时,因为Module 1知道Module 2仅使用 Object 的 7 个方法中的 3 个,所以它仅使用这 3 个方法所需的特定数据部分初始化 Object。一旦Module 2的行为发生了变化,则Module 1的行为也需要发生变化。Module 1将 BaseObject 传递给Module 2。Module 2知道Module 1实际上正在向其传递 DerivedObject,所以它将 BaseObject 转换为 DerivedObject 并调用特定于 DerivedObject 的方法。一旦Module 1传递的实际数据发生了变化,则Module 2的行为也需要发生变化。
语义耦合是危险的,因为当更改了一个模块的代码后,另一个模块的代码也需要相应的修改,而且这个修改往往不是编译器能检测到的(不是语法错误)。这就带来了潜在的 bug。
松耦合的核心是,一个模块提供了有效的,额外的抽象级别——一旦你编写了它,你就可以认为它是理所当然的。
它降低了整个程序的复杂性,让您一次专注于一件事。
如果使用模块需要你同时关注多件事情(了解其内部工作原理、修改全局数据、不确定的功能),则抽象能力就会丧失,模块帮助管理复杂性的能力也会降低或消除。
#寻找常见的设计模式
有些软件问题需要从第一原理出发,找寻出解决方案。但大部分的软件问题都与过去的问题类似,因此也可以用过去类似的解决方案来解决。这些过去的解决方案,就是 设计模式。
设计模式的好处在于:
- 设计模式将常见问题的解决方案制度化,以减少错误:模式代表了解决常见问题的标准化方法,这些方法通常是多年来解决这些方法的智慧的积累。
- 设计模式通过提供现成的抽象来降低复杂度:如果你说“这个类通过单例模式创建实例”,项目中的其他程序员就能很快的理解这段代码的约束。
- 设计模式能带来启发性思考:熟悉设计模式,可以帮助设计者在架构时思考,现有的问题和哪个设计模式解决的问题更类似,使用熟悉的解决方案的组合要比从头制定解决方案简单的多,也更容易让别人理解。
设计模式的潜在风险是:
- 可能存在强行适配一个设计模式的情况:在某些情况下,稍微改变代码以符合公认的模式将提高代码的可理解性。但是,如果代码大范围改动而让强制让其看起来像标准模式,则会增加复杂性。
- 尝鲜:使用模式是因为想要尝试一种模式,而不是因为该模式是合适的设计解决方案。
#其他启发性方法
#寻求高内聚
内聚是衡量一个类中的所有方法,或一个方法内所有的代码,是否是为了一个共同的目的而实现的。
如果一个类中的所有方法或一个方法内所有的代码,都是为了解决同一个问题,那么你的大脑就约容易记住这个类或方法。
#建立层次结构
层次结构(Hierarchy)是一种将信息分层的方式,将概念中最抽象,或最一般的信息放在层次结构的顶部,层次结构越底部就越详细、专用。
另一个降低复杂性的尝试是,仅让系统的一个子集可以被使用:一个简单的公共系统向所有人开放,它由一个隐藏着的一个更大、更复杂的私有系统驱动。
———— 《System, Math and Explosions》 摘抄
使用层次结构是人类组织复杂信息的自然方式:当人画一个房子时,会先画房子的轮廓,再时门窗,然后是细节,而不是从一砖一瓦逐步画出整个房子。
层次结构是实现软件时有用的工具,因为它允许开发者仅关注当前需要关注的细节的级别。而且细节并没有完全消失,它们只是被推到了另一个层次,这样开发者就可以在需要的时候考虑它们,而不是一直考虑所有的细节。
#建立标准
将每个类的接口视为与程序其他部分交互的 契约,是一个很好的思考方向。
通常这种契约会类似:如果你承诺提供数据 x、y 和 z,并且承诺它们将具有特征 a、b 和 c,我承诺在约束 8 内执行操作 1、2 和 3, 9 和 10。
这种契约理论上对于管理程序的复杂性很有用,因为开发者可以安全的忽略任何非契约的行为。但实际上,契约本身的指定会很难。
类似 OpenXR,Vulkan 都是 契约
#为测试而设计
通过询问自己“我该怎么设计这个系统,以方便测试”可以引发有趣的思考过程。比如,这个问题会让你开始思考:
- 是否需要将 UI 部分与系统的其他部分分开,以方便可以独立测试系统的其他部分?
- 是否需要规划每一个子系统,以保证每一个子系统对其他系统有最小依赖?
为测试而设计,往往会产生更正式的类接口,在对于后续的维护是有益的。
#规避失败
Design Paradigms: Case Histories of Error and Judgment in Engineering (Petroski 1994) 一书指出:许多重大桥梁故障的发生都是因为只关注了过去的成功,而没有充分考虑可能的故障。如果设计者仔细考虑桥梁可能失败的方式,而不是仅仅复制其他设计成功的部分,那么像 塔科马海峡吊桥 这样的失败是可以避免的。
在计算机领域中,许多知名的系统中重大的安全漏洞也都类似,如果后者能参考前者的失败原因,那么设计中的许多错误都是能规避的。
#谨慎的选择绑定时间
绑定时间(Binding Time) 是指将一个特定的值与一个变量绑定在一起的时间点。比如将渲染时的分辨率就是一个需要与特定值绑定的变量,绑定时间可以是写代码时(硬编码),也可以是设备启动时(设备存在配置文件决定分辨率),也可以是程序启动时(程序的初始化设置),也可以是运行时(支持用户动态设置)。
如果一个值在很早期就和特定的变量绑定在一起,那么代码往往更简单,但灵活性也往往较差。有时,你可以通过提出以下问题获得良好的设计见解:
- 如果我早点绑定这些值会怎么样?
- 如果我稍后绑定这些值怎么办?
- 如果我在代码中初始化该表会怎么样?
- 如果我在运行时从用户那里读取该变量的值会怎么样?
#建立中心控制点
对于一个需求或问题,最好能在 一个 正确的位置找到所有重要的代码或进行相应的修改。
这样做能降低程序的复杂度:开发者需要寻找某些东西的地方越少,改变就越容易和安全。
#考虑使用蛮力
一种有效的思考方法是 使用蛮力。
有效的蛮力解决方案总比无效的优雅方案要好,现实中很可能需要特别长的时间才能获取到一个有效的优雅的解决方案。
如二分搜索算法的第一个描述是在 1946 年发布的(John Mauchly),但在 1960 才有人发布了可以正确针对任意长度的列表的二分搜索算法(Derrick Henry)。
#画图
图表是一种强大的思考方式,图可以在更高的抽象层次上表示问题。当你需要更笼统的处理问题时,图就是一个很好的工具。
#保持模块化
模块化的目标是让每个例程或类都像一个“黑匣子”:你知道进去什么,知道出来什么,但你不知道里面发生了什么。
思考如何从一组黑匣子组装一个系统,可以提供关于信息隐藏、封装,低耦合等各种信息。
#使用启发式方法的指南
思考一个问题的最有效的指导意见之一就是:不要陷入单一方案。
- 如果用 UML 绘制设计图不起作用,请用语言编写。
- 编写一个简短的测试程序。
- 尝试一种完全不同的方法。
- 考虑一个暴力解决方案。
如果其他一切都失败了,那就离开这个问题,去散散步或者思考一些其他的问题。如果你已经力而为但没有结果,那么暂时的将这个问题抛之脑后往往能比纯粹的 坚持 思考能更快的产生结果。
你不必马上解决整个设计问题,如果你在设计时遇到了困难,你首先要确认一点:你是否有足够的信息解决这个问题。
- 如果你可以在未来,在拥有更多信息的情况下给出一个好的解决方案。为何你一定要在现在,基于不足的信息,给出一个错误的方案?
#5.4 设计实践
上一节中是关于设计时的思考方式,这一节则是在应用设计时的实践。
#迭代
设计是一个迭代的过程。当你进行设计并尝试不同的方法时,你会拥有对整个工程的高级视角和低级视角。
- 从高级视角处理问题,将帮助你获得大局观,这可以更进一步的帮助你正确看待低级细节。
- 从低级视角处理问题,你将获得更多的详细细节,这些细节为高级决策提供了坚实的现实基础。
在高级视角和低级视角之间进行切换是一种健康的动态,它创造了一种比完全从上到下或从下到上建造的结构更稳定的受力结构。
从一种视角切换到另一种视角需要耗费大量的脑力,但这对于创建有效的设计至关重要。
当你做出了一个看似良好的设计尝试时,请不要停止。第二次尝试通常会比第一次尝试得到更好的结果,而且每次你都可以在尝试中学到可以改进整体设计的东西。在许多情况下,使用一种方式解决问题会产生见解,使你能够使用另一种更好的方法解决问题
#分而治之
没有人的头骨大到足以包含复杂程序的所有细节,这也适用于设计。将计划划分为不同的关注领域,然后分别解决每个领域。如果您在某个领域遇到了死胡同,请 迭代。
#从上而下和自下而上的设计方法
“自上而下”和“自下而上”听起来可能有些过时,但它们为面向对象设计的创建提供了宝贵的见解。
- 自上向下的设计从高抽象层次开始。通常你从定义基类开始,在设计的过程中,逐渐增加详细程度,如定义派生类。
- 自下而上的设计从细节开始,努力实现通用性。它通常从具体对象开始,然后根据这些对象的细节找出通用性,并进行抽象操作。
自上而下和自上而下都有各自优点,以下是双方的论据:
#自上而下的论据
自上而下方法背后的指导原则是,人脑一次只能专注于一定数量的细节。如果你从基类开始,逐步将它们分解为更详细的类,你的大脑就不会被迫同时处理太多细节。
需要分解到什么程度才算是设计完成?你应该持续分解,直到你觉得现在直接动手写代码比继续分解设计更容易。
- 如果你的设计程度,是让你没法直观的知道你该如何实现,那么说明分解的程度还不够。
- 如果你的设计程度,对你自己开始实现都有点棘手,那么对于以后处理它的任何人来说都会有点麻烦。
#自下而上的论据
有时,自上而下的方法是如此抽象,以至于很难开始。如果您需要使用更具体的东西,请尝试自下而上的设计方法。
如果你看到一个钉子,你要解决它。
你可以选择直接使用锤子(自下而上)。
而不是选择一个工具,选择一个捶打类工具,选择锤子(自上而下)。
问问自己,“这个系统需要做什么?”毫无疑问,你可以回答这个问题。你可能会确定一些可以分配给具体类的低级职责。例如,你可能知道系统需要格式化特定的报表、计算该报表的数据、将其标题居中、在屏幕上显示报表、在打印机上打印报表等等。在确定了几个低级别的职责后,你通常会开始感到足够舒服,此时可以再次查看高层职责。
当进行自下而上的工作时,需要记住如下步骤:
- 问问自己,这个系统要解决什么问题
- 从问题中确定具体的目标,和各部分的责任
- 识别各部分的共同点,并使用类/对象等进行抽象
- 到第 3 步抽象后的层次,思考这些抽象后的部分有什么共同点,并进一步抽象
- 重复步骤 3 和步骤 4,直到顶层
#没有好坏
自上而下和自下而上策略之间的主要区别在于,一种是分解策略,另一种是组合策略。
- 自上而下:从一般性问题开始,将其分解为可管理的部分
- 自下而上:一个从可管理的部分开始,建立一个通用的解决方案。
这两个方案都有各自的优点和缺点:
自上而下的优点是:
- 它很简单:人擅长将大的东西分解成更小的组件,反之则不然。
- 可以推迟施工细节:由于系统的细节经常会受到干扰而变化(需求变动),因此尽早的直到这些细节应该隐藏在整个结构的哪一部分是有用的。
人们拆乐高并不需要任何的说明书,但是组装乐高却需要说明书。
而且即使有说明书,拼装到最后可能也会出现一些额外的零件,这些零件可能是多余的,也可能是拼装错误导致的,但你不知道是哪种情况。
自下而上的优点是:
- 可以很早的识别所需的实用功能:如果你构建过类似的系统,你可以很快的查看旧系统中的部分并考虑重用
- 可以尽早的识别复杂度:自上而下往往开始时很简单,但有时候底层的复杂度会波及到顶层。而这些波澜会将事情变得比实际需要的更复杂。而自下而上开始时很复杂,但能尽早的识别复杂性,一帮助更好的设计。
总之,自上而下和自下而上的设计并不是相互竞争的策略,他们是互惠互利的。设计是一个启发性的过程的,迭代 的过程,你需要反复实验,多次尝试。
#实验原型制作
有时,除非你更好地理解某些实现细节,否则你无法真正知道设计是否有效。在你知道某个特定数据库组织是否能够满足你的性能目标之前,你可能不知道它是否能胜任工作。毕竟 设计是一个棘手问题。
原型设计是编写需要回答特定设计问题所需要的绝对最少量的一次性代码。
当开发人员没有遵守编写回答问题所需的绝对最少的代码时,原型设计的效果就会很差。
- 你可能会引入额外的问题,进而导致无法准确的回答初始的问题。
- 你如果不将原型代码视为一次性代码,那么这些“半临时,半正式”的代码就会最终出现在生产系统中,这无疑增加了维护的复杂度。
当设计问题不够具体时,原型设计的效果也会很差。
- 这个数据库能工作吗? ——狗屎问题
- 在 X,Y,Z 情况同时发生时,数据是否能支持每秒 1000 个事务的处理 ?—— 好问题
实验原型是软件设计师对抗棘手问题的主要工具,但如果没有纪律性的使用原型,则它会引发更多的棘手问题
#多少设计就足够了?
We try to solve the problem by rushing through the design process so that enough time is left at the end of the project to uncover the errors that were made because we rushed through the design process.
—— Glenford Myers
如果设计下降到你以前完成过的任务级别,或者你对于如何解决非常的确信,你或许就已经完成了设计工作,你可以开始编码。
最大的设计问题往往不是来自知道很困难并且创建了糟糕设计的领域,而是来自认为很简单并且根本没有创建任何设计的领域。
#记录你的设计工作
记录一个设计工作的传统方法是将设计写在正式的设计文档中。但针对小型项目、非正式项目还有一些替代的方式:
- 在代码中体现设计文档:如在注释中记录关键的设计决策
- 在合作软件上上记录下讨论和决策
- 使用相机/截图:将设计在白板或绘图工具中画出来,然后通过拍照或截图获得突破,并嵌入到设计文档中。这种方法只需要使用 1% 的时间,就能获得设计文档 80% 的好处。
#5.2 对流行方法论的评论
在软件工程发展的历程中,设计思路从 “设计一切(BDUF, Big Design Up Front)” 渐渐转换到 “不设计任何东西” 。但对于 BDUF 的替代方案,应当是足够的预先设计(ENUF,Enough Design Up Front)。
对于多少是足够,这是一个主观的判断,没人能完美的做出这样的判断。但虽然你无法完全确定正确的设计程度,但设计到最后的一丝细节和完全不设计,这两个极端的设计程度肯定是错误的。
不要做二极管
The more dogmatic you are about applying a design method, the fewer real-life problems you are going to solve
—— P.J Plauger
将设计看作一个棘手的,草率的,启发式的过程。不要满足于你想到的第一个设计,在必要时做原型试验,然后迭代,迭代,再迭代。最终你会对你的设计满意。
 wechat
wechat alipay
alipay